Its been a while since I used flatMaps in spark, and most often it can be replaced by using Explode. But in my case today, I constructed a list of Rows and then converted them to an actual DF without the painful schema registry using rdd operations.
now, input is kinda messy and I used my convert functions to convert everything into dictionaries should they come in:
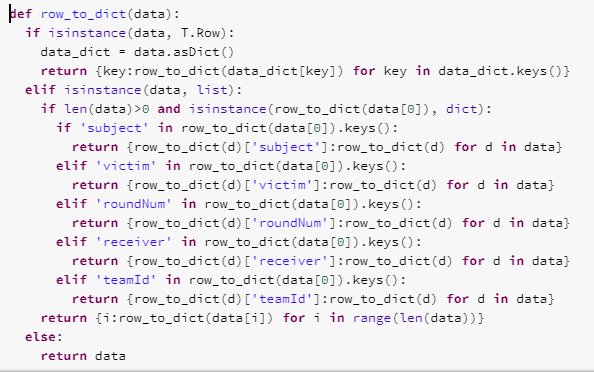
Of course, there are many other processing steps, this is just converting the massively nested data into the ones that I like to see, into easy python dictionaries instead of the nasty spark Row objects.
Now I can do my processing based on the converted data.
After that when I have to save the data, I did something like
def process_df(a,b,c):
....
return [T.Row(**item) for item in processed_data.values()]
so they become one list of Rows. Then, in order to convert the list of Row back to the df, I did this
df = data.rdd.flatMap(lambda x:process_df(x[0], x[1], x[2])).toDF()
there it is! The nested ugly dataframe now has been turned into a flat structure and much easier to get analysis going.
